|
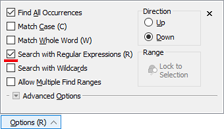
Regular Expressions are a powerful syntax for finding string patterns within a file. Many different flavors of regular expressions exist and 010 Editor uses a syntax similar to Ruby/Perl as implemented by the Oniguruma regular expression library. To search for a regular expression, click the Options button in the Find Bar and enable the Search with Regular Expressions toggle (see the image below). Regular expressions can be used when performing a Find, Replace, Find In Files, or Replace In Files operation. Note that the letter 'R' will appear beside the word Options when regular expressions are enabled. The full syntax of regular expressions are beyond the scope of this document but the following contains an introduction to the major features of regular expressions. Warning: Some regular expressions can be very complex and using certain regular expressions containing lots of repetition operators can cause searches to be performed very slowly.
Matching Characters
Regular expressions look just like regular Find strings. For example, to find a string such as 'Green' just use the regular expression:
Green
Regular expressions use a number of special control characters to control how the searches are done and the special characters are: ".[]^$()/\*{}?+|". To search for any of these control characters include an extra '\' character before the control character. For example, to search for the string "5+6" use the regular expression:
5\+6
A number of special codes can be used to match characters:
- . - any character (except linefeeds)
- \w - a word character include letters, numbers, '_' and unicode characters
- \W - a non word character
- \s - a whitespace character includes tabs and spaces
- \S - a non whitespace chararacter
- \d - a decimal digit chararacter [0-9]
- \D - a non decimal digit character
- \h - a hexadecimal character [0-9a-fA-F]
- \H - a non hexadecimal character
- \t - horizontal tab (0x09)
- \n - newline (0x0A)
- \r - return (0x0D)
- \a - bell (0x07)
- \e - escape (0x1B)
- \f - form feed (0x0C)
- \v - vertical tab (0x0B)
- \nnn - octal character
- \xHH - hexadecimal character
For example, to search for all phone numbers in the form 555-5555 use the regular expression:
\d\d\d-\d\d\d\d
By default, the '.' operator does not match linefeeds but to search across multiple lines see the Multi-Line Regular Expressions section. Note that the case-sensitivity of regular expressions is controlled by the Match Case toggle in the Find Bar Options.
Character Classes
A Character Class or Character Set provides a way to give a number of different options that a single character can match. Character Classes are denoted with '[' and ']' brackets where each character inside the brackets can match. For example, the regular expression:
defen[cs]e
will match both the words 'defence' and 'defense'. Inside of a character class, only the characters "]\-^" are considered control characters. The '-' character can be used to indicate a range of characters. For example the character class:
[0-9a-fA-F]
will match any of the hexadecimal characters. Using the '^' character at the beginning of a character class indicates a negated character class, meaning the regular expression will match any characters that are not in the character class. For example, the character class:
[^abc]
will match any characters that are not a, b, or c.
Anchors
All matching so far has worked by matching a particular character. Regular expressions also support anchors which work by matching a position within a file. The following anchors are supported:
- ^ - beginning of the line
- $ - end of the line
- \b - word boundary
- \B - non word boundary
For example, the regular expression:
^\d\d:\d\d:\d\d
will match a timestamp only if it exists at the beginning of a line. The '\b' anchor can be used to ensure a regular expression matches a whole word. For example the regular expression 'Al' would match both the words 'Al' and 'Alpha' but the regular expression:
\bAl\B
would match 'Al' but not 'Alpha'. The Match Whole Word toggle in the Find Bar Options can be enabled as another way to limit regular expressions to matching whole words only.
Repetition
To match multiple characters in a row, a number of different operators can be used. Some operators are greedy meaning they match the largest number of characters they can, or lazy meaning they match as few characters as they can. The following operators are supported and are by default greedy:
- ? - 1 or 0 times
- * - 0 or more times
- + - 1 or more times
- {n,m} - at least n but not more than m times
- {n,} - at least n times
- {,n} - at least 0 but not more than n times
- {n} - exactly n times
To convert a greedy operator to a lazy operator include an additional '?' after the operator (for example, '??', '*?', or '{n,m}?'. In our phone number example from above for a number such as 555-5555 we could now use:
\d{3}-\d{4}
To match both the strings 'color' and 'colour' use the regular expressions:
colou?r
For another example, to match a simple XML tag use:
<[A-Za-z0-9_/]+>
This regular expression matches one or more alphanumeric characters inside '<' and '>' brackets. Repetition operations can also be used with the '(' and ')' brackets to indicate what is repeating. For example:
reg(ular)? ex(pression)?
matches both the strings 'regular expression' and 'reg ex'. Warning: Using certain combinations of repetition operators can cause searches to be performed very slowly.
Alternation
The alternation operator '|' allows matching one out of several possible regular expressions. For example to search for the colors red, green or blue, use:
red|green|blue
Alternation can be combined with the '(' and ')' brackets to make more complex statements. For example to search for 'const int' or 'const char' use:
const (int|char)
Matching Hex Bytes
When searching for hex bytes use the syntax '\xHH' to denote a hex byte where HH is the byte to find. This syntax must be used for regular expressions even when the Find type is set to Hex Bytes in the Find Bar. For example, to search for the bytes '3F 4D ?? 0F' use the regular expression:
\x3F\x4D.\x0F
Hex bytes can also be used in character classes. For example to search for the first non-zero byte use:
[^\x00]
When regular expressions are enabled, the Find type is set to Hex Bytes and no regular expression is being editing in the Find Bar, pressing Ctrl+F on the keyboard will copy the currently selected hex bytes to the Find Bar using the \x notation.
Multi-Line Regular Expressions
By default the '.' operator does not match linefeeds so expressions containing '.*' would not span across multiple lines. For example, if searching for C-style comments /* and */ the following regular expression could be used but it would only match if /* and */ were on the same line:
\/\*.*?\*\/
A few options exist to search across multiple lines. The first is to use '[\x00-\xff]' instead of '.', for example:
\/\*[\x00-\xff]*?\*\/
The second option is to prepend '(?m)' to the regular expression which changes '.' to match linefeeds. For example:
(?m)\/\*.*?\*\/
Replacements
If using regular expressions when doing a replace, a number of special codes can be used in the Replace field such as \t, \n, \r, \a, \e, \f, \v, \xHH as discussed in the Matching Characters section above. Use \\ to specify a single backslash or $$ to indicate a single $. Capture groups can also be used as discussed in the next section.
Capture Groups
A capture group allows text that matches part of a regular expression to be inserted into a replacement. To create a capture group, enclose part of the regular expression to find inside brackets ( and ). The bytes which match the regular expression inside the first pair of brackets is called capture group 1, bytes which match the next expression are called capture group 2, etc. The following syntax can be used in the replace string to create back-references to the capture groups:
- \1 up to \9 - specify the capture groups 1 up to 9
- \k<n> - where n is any number and can be used for capture groups 10 or greater
- \k<name> - specify a named capture group as discussed below
- \0 - indicates the bytes that match the whole regular expression
- $1 up to $9 - specify the capture groups 1 up to 9
- ${n} - where n is any number and can be used for capture groups 10 or greater
- ${name} - specify a named capture group as discussed below
- $0 - indicates the bytes that match the whole regular expression
For example, if a file contains the value "19.10.2018" and the following replacement is done:
- Find Expression: (\d{2})\.(\d{2})\.(\d{4})
- Replace Expression: \3-\2-\1
Then the result would be "2018-10-19". Capture groups can also be assigned names, which makes managing large number of groups easier. To create a named capture group use the syntax (?<name>...) in the Find regular expression. For example, for the file "19.10.2018" and the following replacement:
- Find Expression: (?<day>\d{2})\.(?<month>\d{2})\.(?<year>\d{4})
- Replace Expression: ${year}-${month}-${day}
then the result again would be "2018-10-19".
Functions
Regular expressions can be used in scripts using the FindAll, FindFirst, FindInFiles or ReplaceAll functions and the 'method=FINDMETHOD_REGEX' parameter. Regular expressions can also be used to search within strings using the RegExMatch or RegExSearch functions.
| 


